Kapitel S3
Der statistische Klimaantriebs-Generator
Zur Simulation und Analyse der Auswirkungen
des Klimawandels auf die Wasserressourcen der
Oberen Donau werden Klimawirkungsmodelle
mit meteorologischen Daten angetrieben, in denen
szenariobasierte Klimatrends wiedergegeben
sind. Die Ergebnisse der Szenario-Simulationen
und die daraus gezogenen Schlüsse hängen wesentlich sowohl von den Annahmen zu
den zukünftigen Klimatrends wie auch von Verfügbarkeit,
Art und Qualität des meteorologischen
Antriebs ab.
In GLOWA-Danube besteht der meteorologische
Antrieb der Klimawirkungsmodelle aus einer
Zeitserie von Feldern der meteorologischen
Parameter Niederschlag, Strahlung (einkommend
kurz- und langwelliger Anteil), Lufttemperatur,
Luftfeuchte und Windgeschwindigkeit. Diese
Felder werden von den Wirkungsmodellen in einer räumlichen Auflösung von 1 x 1 km² und in einer
zeitlichen Auflösung von 1 h erwartet. Für die
Vergangenheit wird der meteorologische Antrieb
in GLOWA-Danube aus Daten meteorologischer
Messnetze durch raumzeitliche Interpolation erzeugt
(siehe Kapitel 1.5-1.7). Dieser Antrieb dient
u.a. zur Validierung der hydrologischen Klimawirkungsmodelle.
Dieses Vorgehen ist für Szenarien,
die die Zukunft behandeln, nicht möglich. Es
gilt deshalb über unterschiedliche Verfahren die
meteorologischen Antriebe zur Simulation von
Zukunftsszenarien bereitzustellen.
Als Quelle für den meteorologischen Antrieb können
Ergebnisse regionaler Klimamodelle, wie von
MM5, REMO oder CLM, dienen. Zwar liefern die
Ergebnisse von REMO und MM5 stündliche Werte,
da aber die räumliche Modellskala der regionalen
Klimamodelle in der Regel gröber als 1 km
ist, müssen ihre Ergebnisse durch einen Downscaling-Prozess der Modellskala der Klimawirkungsmodelle
von DANUBIA angepasst werden.
Hinzu kommen Verfahren zur Beseitigung systematischer
Verzerrungen in den Ergebnissen der
regionalen Klimamodelle, die als Bias-Korrekturen
bezeichnet werden. Die dazu entwickelten
Ansätze, die dabei auftretenden Probleme und
die erzielten Ergebnisse werden ausführlich in
Kapitel S5 beschrieben.
Als weitere Quelle meteorologischer Antriebe
bietet sich an, die historischen Messdaten der
meteorologischen Messnetze auf geeignete Weise
so neu zusammenzustellen, dass der dem jeweiligen
Szenario zugrunde gelegte Klimatrend
wiedergegeben wird. Der dazu entwickelte statistische
Klimaantriebs-Generator, der im Weiteren
vorgestellt wird, gehört zur Familie der Wettergeneratoren
und dort zu den „nearest-neighbour
resampling“ Ansätzen (Yates et al. (2003), Buishand
and Brandsma (2001), Young (1994), Orlowsky
et al. (2007)). Er verzichtet im Gegensatz
zu wetterlagenabhängigen Ansätzen (Spekat et
al., 2006) auf die Analyse der jeweiligen Wetterlage,
generiert dafür aber stündliche Felder eines
szenariobasierten zukünftigen Witterungsverlaufs.
Der Klimaantriebs-Generator beruht auf der
Annahme, dass in der Vergangenheit bereits gemessene
Witterungsverläufe in ähnlicher Weise
auch in Zukunft auftreten werden, allerdings in
unterschiedlicher Reihenfolge und Häufigkeit. Als
Zeitintervall zur Charakterisierung eines Witterungsverlaufs
wird eine Woche gewählt. Der Witterungsverlauf
einer Woche in der Vergangenheit
wird durch die wöchentliche Mitteltemperatur und
mittlere Niederschlagssumme über alle Messstationen
im Einzugsgebiet der Oberen Donau charakterisiert.
Der weitere Prozess der Erzeugung
synthetischer meteorologischer Antriebe aus
meteorologischen Messungen besteht aus drei
Schritten:

Abbildung S3.1: Schematisches Vorgehen bei der Erzeugung
von zukünftigen meteorologischen Eingabedatensätzen
mit Hilfe des statistischen Klimaantriebs-Generators.
Schritt 1: Statistische Analyse der historischen
Messdaten der Klimamessnetze
Im ersten Schritt werden die verfügbaren Daten
des klimatologischen Messnetzes des DWD und
des Österreichischen Wetterdienstes (siehe
Kapitel 1.4) einer statistischen Analyse unterzogen.
Dazu werden aus den Messdaten aller verfügbaren
Stationen für jede wöchentliche Witterungsperiode
Mitteltemperatur und gemittelte
Niederschlagssumme aller Stationen im Untersuchungsgebiet
bestimmt. Die Woche wurde als
Zeitintervall gewählt, da sie gut mit der charakteristischen
Zeitdauer der Wetterlagen im Untersuchungsgebiet
korrespondiert. Sowohl Tief- als
auch Hochdruckgebiete weisen in etwa diese
Zeitdauer auf. Für jede Woche des verfügbaren
historischen Datensatz der 47 Jahre von 1960 bis
2006 erhält man damit je einen Wert für die Mitteltemperatur
und für die gemittelte Niederschlagssumme.
Für jede Woche des Jahres werden danach
die 47 erhaltenen Wertepaare der Jahre
1960 bis 2006 einer linearen Regressionsanalyse
unterzogen. Sie ergibt für jede Woche des
Jahres für den betrachteten historischen Zeitraum
die drei Größen mittlere Mitteltemperatur,
mittlere gemittelte Niederschlagssumme sowie
die Kovarianzmatrix zwischen beiden Größen.
Die Kovarianzmatrix gibt sowohl Aufschluss über
die Variabilität der Mitteltemperatur und der
gemittelten Niederschlagssumme aller Stationen
als auch über die Korrelation zwischen beiden
Größen über den untersuchten Zeitraum. Zusammengenommen
ergibt die Analyse den jahreszeitlichen
Verlauf der genannten Größen und ihrer
Kovarianz als wesentliche Charateristika des
regionalen Klimas der betrachteten Periode. Der
aus den wöchentlichen Kovarianzmatrizen bestimmte
wöchentliche Verlauf des Korrelationskoeffizienten
zwischen Mitteltemperatur und gemittelter
Niederschlagssumme im Analysezeitraum
1960-2006 ist in Abbildung S3.2 dargestellt.
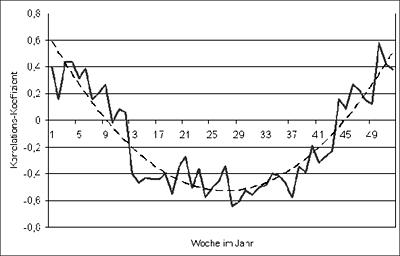
Abbildung S3.2: Verlauf des wöchentlichen linearen Korrelationskoeffizienten
zwischen Mitteltemperatur und Niederschlagssumme
der Stationen der klimatologischen
Messnetze im Einzugsgebiet der Oberen Donau; Analysezeitraum:
1960-2006.
Abbildung S3.2 zeigt eine deutlich positive Korrelation
mit einem Korrelationskoeffizienten von
ungefähr 0.4 um die Wochen 1 und 52. Dies bedeutet,
dass eine Tendenz besteht, dass in diesen
Wochen bei erhöhten mittleren Lufttemperaturen
im Untersuchungsgebiet auch überdurchschnittlich
viel Niederschlag fällt. Dieser Trend
kehrt sich für die Sommerwochen 25 bis 28 um.
Hier herrscht negative Korrelation, was bedeutet,
dass in Wochen mit erhöhter mittlerer Lufttemperatur
unterdurchschnittlich viel Niederschlag fällt.
Beide Ergebnisse sind leicht nachzuvollziehen.
Während im Winter eine überdurchschnittliche
Temperatur im Untersuchungsgebiet i.d.R. mit
südlichen Anströmrichtungen und erhöhtem
Wasserdampfgehalt und damit mit mehr Niederschlag
verbunden ist, ist eine erhöhte Temperatur
im Sommer i.d.R. mit ochdruckwetterlagen und
damit reduziertem Niederschlag verbunden. In
den Übergangsjahreszeiten um die Wochen 10
und 44 ist keine Korrelation vorhanden und damit
auch keine Tendenz zu erkennen.
Der wöchentliche Verlauf der statistischen Kenngrößen
Mitteltemperatur, Niederschlagssumme
und ihre Kovarianzmatrix charakterisieren somit
im gewählten Ansatz das Klima des historischen
Untersuchungszeitraums. Nachdem die Analyse
des historischen Klimas damit abgeschlossen ist,
dienen die nächsten Schritte dazu, in einem umgekehrten
Prozess mit Hilfe der statistischen
Kenngrößen mögliche Witterungsverläufe eines
zukünftigen Klimatrends zu synthetisieren. Dazu
benötigt man zunächst wöchentliche Daten für
Mitteltemperatur und mittlere Niederschlagssumme
für den zukünftigen Szenariozeitraum.
Schritt 2: Synthese von wöchentlichen Klima-
Zeitreihen aus einem vorgegebenen Klimatrend
In Schritt 2 wird für einen gewählten regionalen
Klimatrend (siehe Kapitel S2) für den Zeitraum
von 2011 bis 2060 der zeitliche Verlauf der wöchentlichen
Mitteltemperatur und der mittleren
Niederschlagssumme bestimmt. Um für die Zukunft
wöchentliche Wertepaare für die Mitteltemperatur
und die Niederschlagssumme zu erhalten,
werden vier Komponenten zeitlich überlagert:
- die dem Klimatrend folgende Veränderung der
jährlichen Mitteltemperatur
- die jahreszeitliche Veränderung der Mitteltemperatur
- die dem Klimatrend folgende Veränderung der
mittleren Niederschlagssumme für jede Woche
im Jahr
- die statistisch-zufällige Schwankung von wöchentlicher
Mitteltemperatur und Niederschlagssumme
Das Zusammenspiel der 4 Komponenten ist in
Abbildung S3.3 a-f exemplarisch für die Erzeugung
einer synthetischen wöchentlichen Klimazeitreihe
für den Zeitraum von 2011 bis 2060
dargestellt.
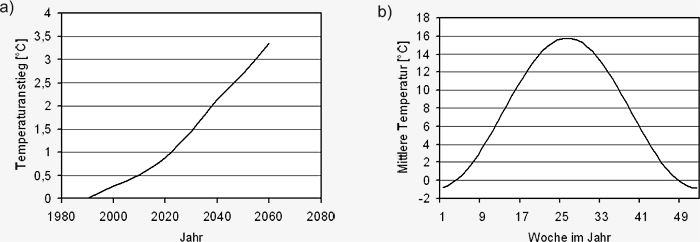
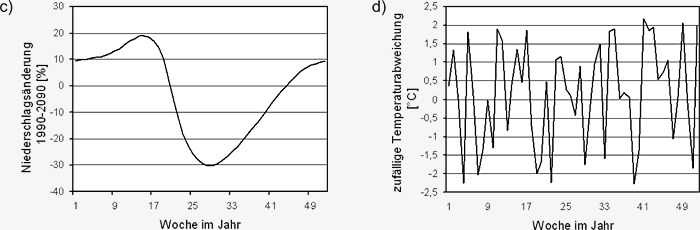
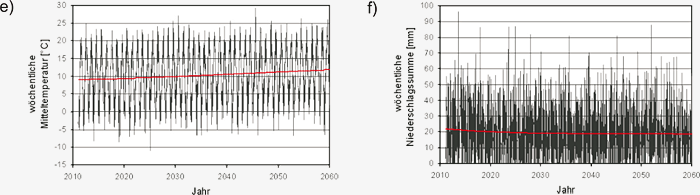
Abbildung S3.3: Schematische exemplarische Darstellung
der Erzeugung synthetischer wöchentlicher Zeitreihen von
Mitteltemperatur und mittlerer Niederschlagssumme mit
Hilfe des statistischen Klimaantriebs-Generators: a) angenommener
Temperaturtrend an der Oberen Donau nach
IPCC-A1B und einer Erwärmung von 5°C von 1990 bis
2100; b) Verlauf der wöchentlichen Mitteltemperatur im Untersuchungsgebiet
1960-2006; c) angenommener Niederschlagstrend
als prozentuale Veränderung der wöchentlichen
Niederschlagssumme zwischen 1990 und 2100 von
Jacob et al. (2008); d) statistische Variabilität der wöchentlichen
Mitteltemperatur aus den Kovarianzmatrizen der
meteorologischen Daten von 1960-2006; e) Kombination
von a), b) und d) zu einer Zeitreihe der wöchentlichen Mitteltemperatur
2011-2060 ; f) Kombination von a), c) und d)
zu einer Zeitreihe der wöchentlichen Niederschlagssumme
2011-2060.
Es wird bei diesem fiktiven Beispiel angenommen,
dass der Temperaturanstieg von 1990 bis
2100 im Untersuchungsgebiet einen Wert von
5°C betragen soll und in seinem Verlauf dem
A1B-Szenario entsprechen soll (siehe Abbildung
S3.3a), die jahreszeitliche Variation der Temperatur
ist in Abbildung S3.3b dargestellt. Die angenommene
prozentuale Veränderung des wöchentlichen
Niederschlags von 1990 bis 2100 ist
im vorliegenden Fall einer Trendanalyse des
REMO-UBA Szenarios entnommen und in Abbildung
S3.3c dargestellt. Sie wird der Temperaturerhöhung
folgend für die laufenden Jahre anteilsmäßig
berücksichtigt. Abbildung S3.3d stellt
die berechnete statistische Schwankung der
Temperatur für ein beliebig herausgegriffenes
Beispieljahr aus der Zeitserie von 2011 bis 2060
dar. Sie wurde mit einem Zufallsgenerator (Visual
Numerics, 2006) aus den wöchentlichen Kovarianzmatrizen
von Mitteltemperatur und Niederschlag
bestimmt. Entsprechende statistische
Schwankungen lassen sich durch fortgesetzte
Anwendung des Zufallsgenerators für jede Woche
des untersuchten Zeitraums bestimmen.
Eine synthetische Zeitreihe für den Verlauf der
wöchentlichen Mitteltemperaturen der Jahre von
2011 bis 2060 entsteht nun, indem man den Temperaturtrend,
die jahreszeitlichen Variationen der
Temperatur und die statistischen Variabilitäten aller
Wochen von 2011 bis 2060 überlagert. Der
sich aus der Überlagerung ergebende Verlauf der
wöchentlichen Mitteltemperaturen von 2011 bis
2060 ist in Abbildung S3.3e dargestellt. Neben
den jahreszeitlichen Schwankungen sind der
Trend (rote Linie) und die statistische Variabilität
der Temperaturen klar zu erkennen. Die Erzeugung
der Zeitreihe der wöchentlichen Niederschlagssummen
geschieht entsprechend aus
den Abbildungen S3.3a, S3.3c und einer Abbildung
S3.3d entsprechenden statistischen
Schwankung der mittleren Niederschlagssumme,
wobei der Trend für seine jahreszeitliche Veränderung
berücksichtigt wird und mit dem Zufallsgenerator
die statistische Schwankung der
Niederschlagssummen simuliert wird. Eine Zeitreihe
der sich ergebenden wöchentlichen Niederschlagssummen
für den Zeitraum von 2011
bis 2060 ist in Abbildung S3.3f dargestellt.
Bei der Bestimmung der statistischen Variabilitäten
ist zu berücksichtigen, dass wöchentliche Mitteltemperatur
und mittlere Niederschlagssumme
voneinander abhängig sind. Diese Abhängigkeit
folgt, wie in Abbildung S3.2 dargestellt, einem
jahreszeitlichen Verlauf. Dies hat zur Folge, dass
eine für die Temperatur mit dem Zufallsgenerator
ermittelte zufällige positive Abweichung vom jeweiligen
wöchentlichen Mittelwert im Winter auch
in einer zufälligen, positiven Abweichung der Niederschlagssumme
resultiert. Für die Sommermonate
gilt nach Abbildung S3.2 entsprechend eine
negative, auch zufällige, Abweichung. Um die gegenseitige
Abhängigkeit der beiden Größen bei
der Erzeugung der Variabilitäten zu berücksichtigen,
wurde der zwei-dimensionale Zufallsgenerator
RNMVN der IMSL-Statistik-Bibliothek (Visual
Numerics, 2006) benutzt. Er bestimmt bei
jedem Aufruf (also für jede Woche) auf der Grundlage
der Mittelwerte und Kovarianzmatrizen unter Annahme der Normalverteilung der beteiligten
Größen zwei voneinander abhängige, normal
verteilte Zufallszahlen für die wöchentliche Mitteltemperatur
und die wöchentliche mittlere Niederschlagssumme.
Mit dem Zufallsgenerator
werden für jede Woche der Zeitreihe von 2011-2060 auf Grundlage der jeweils unterschiedlichen
Mittelwerte und Kovarianzen unterschiedliche
Wertepaare von Mitteltemperatur und Niederschlagssumme
ermittelt. Der zeitliche Verlauf
des Zufallsanteils der erzeugten Zeitreihe ist
durch den Startwert des Zufallsgenerators bestimmt.
Unterschiedliche Startwerte erzeugen reproduzierbar
unterschiedliche, statistisch äquivalente
Verläufe des Zufallsanteils.
Als Resultat von Schritt 2 können nun voneinander
abhängige synthetische, zukünftige Zeitreihen
von wöchentlicher Mitteltemperatur und Niederschlagssumme
für den Zeitraum von 2011 bis
2060 erzeugt werden. Folgende Annahmen wurden
bei der Erzeugung der Zeitreihen in Abbildung
S3.3e und Abbildung S3.3f gemacht:
- im gewählten Zeitraum von 2011 bis 2060 werden
sich Mitteltemperaturen und Niederschlagssummen
nach einem jeweils zugrundeliegenden
Klimatrend ändern. Die in
GLOWA-Danube verwendeten Klimatrends
sind ausführlich in Kapitel S2 dargestellt. Der
Klimaantriebs-Generator ist in seiner Funktionsfähigkeit
nicht auf die in S2 dargestellten
Klimatrends beschränkt und kann damit unmittelbar
von den Fortschritten der Forschung
zum regionalen Klimawandel profitieren.
- die zukünftige jahreszeitliche Amplitude der
wöchentlichen Mitteltemperaturen wird sich,
auch wenn die Temperaturen ansteigen werden,
nicht wesentlich ändern. Diese Annahme
stützt sich auf die Aussagen des IPCC (2007),
nach denen die Region der Oberen Donau
zwar eine deutliche Zunahme der mediterranen
Klimakomponente erfahren wird, der Klimawandel
aber nicht zu gänzlich neuen Witterungsverläufen
führen wird.
- die Kovarianzen von wöchentlicher Mitteltemperatur
und mittlerer Niederschlagssumme
und ihre in Abbildung S3.2 gezeigte gegenseitige
Abhängigkeit wird sich im Zeitraum von
2011 bis 2060 nicht wesentlich ändern. Diese
Annahme ermöglicht es, die aus den Daten
der Periode 1960-2006 ermittelten Kovarianzmatrizen
für die Ermittlung der statistischen
Schwankungen in den Szenario-Klima-Zeitreihen
zu verwenden. Auch hier gilt die Annahme,
dass das Einzugsgebiet der Oberen
Donau trotz Klimawandel in der heutigen Klimazone
verbleiben wird.
Schritt 3: Erzeugung neuer Datenreihe durch
Neugruppierung historischer Daten
Die in Schritt 2 erzeugten wöchentlichen Zeitreihen
der Mitteltemperatur und der mittleren
Niederschlagssumme reichen als meteorologische
Eingaben für DANUBIA nicht aus. DANUBIA
benötigt stündliche Felder der meteorologischen
Parameter mit einer räumlichen Auflösung
von 1 x 1 km².
In Schritt 3 werden nun auf der Grundlage der Ergebnisse
von Schritt 2 für den Zeitraum von 2011
bis 2060 aus den historischen meteorologischen
Datensätzen des Deutschen und Österreichischen
Wetterdienstes, die als Grundlage für die
Validierung von DANUBIA dienten, die zukünftigen
meteorologischen Datensätze durch Neugruppierung
erzeugt.
Der Grundgedanke beim weiteren Vorgehen ist,
dass die in Schritt 1 aus den historischen Zeitreihen
ermittelten wöchentlichen Mitteltemperaturen
und mittlere Niederschlagssummen den Witterungsverlauf
der betrachteten Woche im gesamten
Untersuchungsgebiet charakterisieren
und damit für den Zugriff auf die in einer Datenbank
wöchentlich abgelegten Messwerte aller
benutzten Stationen einen Schlüssel bilden können.
Für die Szenario-Zeitreihe von wöchentlicher
Mitteltemperatur und mittlerer Niederschlagssumme
als Ergebnis von Schritt 2 wird
nun in der Datenbank für jede Woche diejenige
historische Woche gesucht, die die ähnlichste
Kombination von wöchentlicher Mitteltemperatur
und Niederschlagssumme aufweist. Der komplette
Datensatz der jeweils ausgewählten historischen
Woche wird für die betrachtete Szenario-Woche übernommen. Er besteht aus allen meteorologischen Messdaten aller Stationen im Untersuchungsgebiet
und bildet einen Satz in sich
konsistenter, weil gemessener, meteorologischer
Stationsdaten. Nachdem man dieses Vorgehen
für alle Wochen der Periode 2011 bis 2060 durchgeführt
hat, erhält man einen auf historischen
Messdaten beruhenden, neu gruppierten meteorologischen
Datensatz für den gesamten Szenariozeitraum.
Er besteht zum einen aus gleichzeitigen
historischen Messungen der benutzten Stationen
und zeichnet zum anderen den gewählten
zukünftigen Klimatrend nach.
Zur Identifikation derjenigen historischen Woche,
die der zukünftigen Woche klimatologisch
am ähnlichsten ist, wurde das maximum-likelihood
Kriterium herangezogen. Dafür wird der
Mahalanobis-Abstand zwischen allen historischen
und der betrachteten zukünftigen Woche
im Merkmalsraum, der durch die wöchentliche
Mitteltemperatur und mittlere Niederschlagssumme
aufgespannt wird (Mahalanobis, 1936), als
Maß für die klimatologische Ähnlichkeit berechnet.
Es berücksichtigt unter der Voraussetzung
von Normalverteilungen durch Nutzung der
Mittelwerte und Kovarianzen die unterschiedliche
Streuung von Mitteltemperatur und mittlerer Niederschlagssumme
sowie die Abhängigkeit beider
Größen voneinander. Dieses Maß ist umgekehrt
proportional zur Wahrscheinlichkeit, dass eine
gesuchte historische Woche den gleichen Witterungsverlauf
aufweist wie die untersuchte Referenzwoche
im Szenario. Diejenige historische
Woche, die den kleinsten Mahalanobis-Abstand
zur betrachteten Szenario-Woche aufweist und
ihr damit in ihrem Witterungsverlauf am ähnlichsten
ist, wird in den neuen Datensatz übernommen,
unabhängig davon, wann im Jahr sie aufgetreten
ist.
Abbildung S3.4 zeigt exemplarisch den Mahalanobis-Abstand für alle Wochen von 2011 bis
2060 für die Klimavariante Baseline (siehe Kapitel
S4) des Klimatrends Fortschreibung (siehe
Kapitel S2). Der Mahalanobis-Abstand zeigt im
betrachteten Szenario-Zeitraum keinen zeitlichen
Trend. Dies bedeutet, dass sich die mittlere
Ähnlichkeit zwischen den in Schritt 2 bestimmten
zukünftigen wöchentlichen Mittelwerten und den
gewählten, in der Vergangenheit gemessenen,
wöchentlichen Mittelwerten während des Szenario-Zeitraums von 2011-2060 nicht ändert. Ein
Anstieg des Mahalanobis-Abstandes mit der Zeit
würde bedeuten, dass die Ähnlichkeit der Szenario-Wochen aus Schritt 2 mit der aus den gemessenen
Wochen jeweils gewählten Woche mit
zukünftig stärkerem Einfluss des Klimawandels
immer schwächer würde. Dies wäre ein Zeichen
dafür, dass im Szenario vermehrt Wochen auftreten,
für die man in der Vergangenheit keine
Entsprechung findet und die somit so in der Vergangenheit
nicht gemessen wurden.
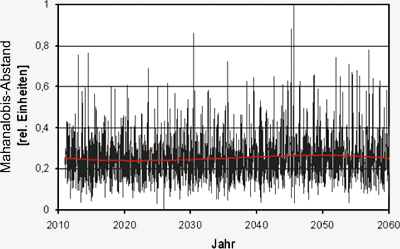
Abbildung S3.4: Mahalanobis-Abstand zwischen der gewählten
historischen und der zukünftigen Woche auf der
Grundlage von wöchentlicher Mitteltemperatur und Niederschlagssumme.
Nach Ausführung der Schritte 1-3 steht ein neuer
meteorologischer Antrieb zur Verfügung, der einen
definierten Temperaturtrend aufweist, einer
vorgegebenen zeitlichen Veränderung des Niederschlags
folgt und die gleichen Variabilitäten
wie der gemessene historische Datensatz aufweist.
Er besteht aus räumlich und physikalisch
konsistenten, weil gemessenen, Daten in gleichem
Format, gleicher Güte und gleicher räumlicher
und zeitlicher Auflösung wie diejenigen historischen
Daten, die zur Validierung von DANUBIA
benutzt wurden. Aus ihm wird dann, wie im
Fall der Validerung von DANUBIA, durch raumzeitliche
Interpolation der meteorologische Szenario-Antrieb erstellt.
Neben diesen Vorteilen besitzt das beschriebene
Vorgehen auch Nachteile. So sind extreme Starkniederschläge, die über die bereits erfassten
Niederschlagsereignisse hinaus gehen, nicht
darstellbar. Auch kann eine Veränderung der Persistenz
von Wetterlagen für Zeiträume, die über
eine Woche hinausreichen, nicht berücksichtigt
werden und es entstehen, zufällig verteilt, zwischen
angrenzenden Wochen Sprünge, die in ihrem
Ausmaß allerdings nicht über das in der Natur
beobachtete hinaus gehen. Das vorgestellte
Verfahren des statistischen Klimaantriebs-Generators
ist aber durchaus in der Lage neue, bisher
nicht aufgetretene Feucht- oder Trockenperioden
zu generieren, indem der ansteigende Temperaturtrend
häufigere und länger andauernde Aneinanderreihungen
bisheriger wöchentlicher Trokken-
bzw. Feuchtperioden hervorbringt.
Wöchentliche Verläufe der Klimatrends
Der Klimaantriebs-Generator wurde bisher in seiner
prinzipiellen Funktionsweise exemplarisch
dargestellt. Er bildet eine Grundlage für die weitere
Umsetzung der in Kapitel S2 vorgestellten vier
Klimatrends. Neben dem jährlichen Temperaturtrend
wird im statistischen Klimaantriebs-Generator
damit für jeden Klimatrend neben dem Jahresgang
der Veränderung der wöchentlichen Mitteltemperatur
auch die Veränderung der wöchentlichen
Niederschlagssumme als Eingabe
benötigt. Es gilt also, die wöchentliche Verteilung
der Niederschlagsänderung aus den jahreszeitlichen
Angaben zu den möglichen Niederschlagsänderungen
in Tabelle S2.4 des Kapitels S2 abzuleiten.
Dies geschieht durch Interpolation zwischen
den in der Tabelle vorgegebenen Stützstellen
unter Sicherstellung der vorgegebenen
jahreszeitlichen Mittelwerte der Veränderung.
Für den wöchentlichen Verlauf der Veränderung
der Niederschlagssumme zwischen 1990 und
2100 wurde im Klimatrend IPCC regional der in
Abbildung S3.5 aufgezeigte Verlauf interpoliert.
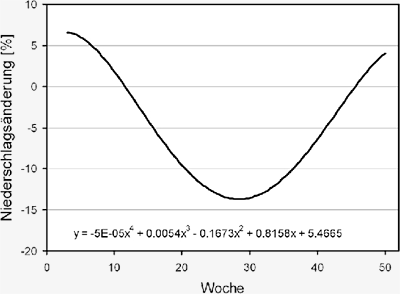
Abbildung S3.5: Wöchentlicher Verlauf der prozentualen
Veränderung des Niederschlags im Einzugsgebiet der
Oberen Donau aus dem Vergleich der Ergebnisse der globalen
Modelle nach IPCC (2007) im Zeitraum von 1990 bis
2100.
Die jahreszeitlichen Angaben zur Veränderung
des Niederschlags und der Temperatur der regionalen
Klimatrends von REMO und MM5 (siehe
Kapitel S2, Tabelle S2.4) erlauben eine Interpolation
sowohl auf wöchentliche prozentuale Veränderungen des Niederschlags als auch auf wöchentliche
Temperaturänderungen für die Periode
1990-2100. Auch hier wurde die Interpolation
so durchgeführt, dass die jahreszeitlichen Durchschnittswerte
bei der Interpolation erhalten bleiben.
Die Ergebnisse sind in Abbildung S3.6 zu sehen.
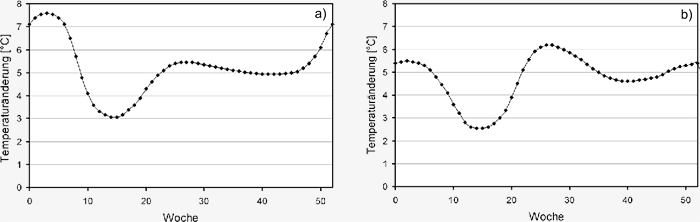
Abbildung S3.6: Wöchentlicher Verlauf der Veränderung
der Temperatur im Einzugsgebiet der Oberen Donau auf
Basis der saisonalen Ergebnisse a) des regionalen Klimamodells
REMO nach Jacob et al. (2008) und b) des regionalen
Klimamodells MM5 im Zeitraum von 1990 bis 2100.
Der wöchentliche Verlauf der Temperaturänderung
von REMO in Abbildung S3.6a weist mit
mehr als +7°C in der Spitze ein ausgeprägtes Maximum
im Spätwinter auf. Demgegenüber fällt der
Temperaturanstieg im Frühjahr mit minimal 3°C
bedeutend geringer aus. In den restlichen Jahreszeiten
bewegt er sich um die 5°C. Die Änderungen
der Temperaturen bei MM5 bewegen sich
in derselben Größenordung, sind allerdings in ihren
jahreszeitlichen Schwankungen deutlich weniger
ausgeprägt. Das Minimum des Temperaturanstiegs
liegt bei beiden Modellergebnissen im
Frühjahr.
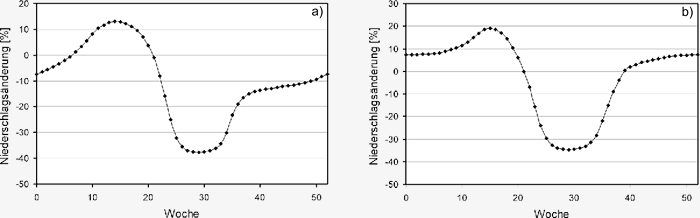
Abbildung S3.7: Wöchentlicher Verlauf der prozentualen
Veränderung des Niederschlags im Einzugsgebiet der
Oberen Donau auf Basis der saisonalen Ergebnisse a)
des regionalen Klimamodells REMO nach Jacob et al.
(2008) und b) des regionalen Klimamodells MM5 im Zeitraum
von 1990 bis 2100.
Die Veränderung des Niederschlags im Einzugsgebiet
nach IPCC (siehe Abbildung S3.5) und der
regionalen Klimamodellierung mit REMO (siehe
Abbildung S3.7a) unterscheiden sich in ihrem generellen
Trend vor allem im Winter. Hier zeigt
IPCC eine Zunahme des Niederschlags, während
bei der REMO-Simulation der Niederschlag
im betrachteten Zeitraum abnimmt. REMO zeigt
dem gegenüber eine deutliche Zunahme des Niederschlags
in den Frühjahrsmonaten. Insgesamt
sind die jahreszeitlichen Veränderungen in den
Ergebnissen des regionalen Klimamodells
REMO bedeutend stärker ausgeprägt als in den
gemittelten Ergebnissen der globalen Klimamodelle.
Dasselbe gilt generell auch für die Ergebnisse
der regionalen Klimamodellierung mit MM5, wobei
der Trend zur Austrocknung bei MM5 gegenüber
REMO gedämpfter ausfällt. Auch hier nimmt
allerdings der Niederschlag bis 2100 am stärksten
im Frühjahr zu, im Winter ist ebenfalls eine
Zunahme des Niederschlags zu verzeichnen
während auch MM5 eine deutliche Reduzierung
der Niederschläge während der Sommermonate
zeigt.
Für den vierten gewählten Klimatrend, die Fortschreibung des weiteren Temperaturverlaufs auf
Basis der bereits gemessenen historischen Temperaturerhöhungen,
ist eine Abschätzung der wöchentlichen
zukünftigen Veränderungen des Niederschlags
in Form jahreszeitlicher prozentualer
Veränderungen aufgrund der in Kapitel 1.9 bereits
gezeigten geringen statistischen Signifikanz der
historischen Niederschlagstrends nicht angebracht.
Für die Ermittlung der möglichen zukünftigen
Niederschlagsänderung musste daher eine
andere Strategie gewählt werden.
Diese besteht darin, den in den historischen
Messdaten enthaltenen statistischen Zusammenhang
zwischen der wöchentlichen Mitteltemperatur
und der wöchentlichen Niederschlagssumme
zu analysieren. Hierfür wurde für jede Woche im Jahr für die 47 vorliegenden Messjahre
eine lineare Regressionsanalyse durchgeführt.
Die sich im Verlauf des Jahres ändernde Beziehung
zwischen beiden Größen ist in den Abbildungen
S3.8a-c zusammengefasst. In Abbildung
3.8a ist die Sensitivität der mittleren Niederschlagssumme
gegenüber Temperaturänderungen
als Steigung der Regressionsgeraden für jede
Woche im Jahr aufgetragen. In Abbildung 3.8b
ist der Achsenabschnitt der Regressionsgeraden
dargestellt, Abbildung 3.8c stellt den wöchentlichen
Korrelationskoeffizienten der Regressionsgeraden
dar. Abbildung 3.8c zeigt deutlich positive
Korrelationskoeffizienten im Winter und negative
Korrelationskoeffizienten im Sommer. Wenn
man für die Zukunft annimmt, dass sich diese Beziehungen
nicht verändern, bedeutet dies bei
steigenden Lufttemperaturen steigende Niederschläge
im Winter und sinkende Niederschläge
im Sommer. Dies entspricht den Ergebnissen des
IPCC und mit Einschränkungen auch des UBA in
Abbildung S3.6 und S3.7 Die gezeigten wöchentlichen
Beziehungen können nun dazu genutzt
werden, um die mit dem zukünftigen Temperaturanstieg
verbundenen Niederschlagsänderungen
zu quantifizieren.
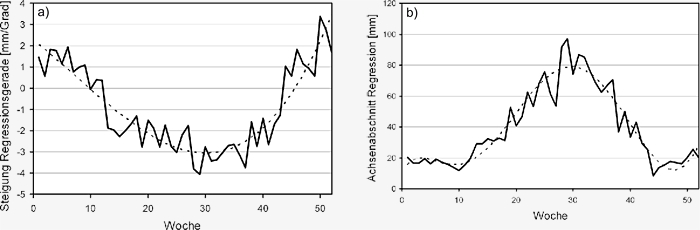
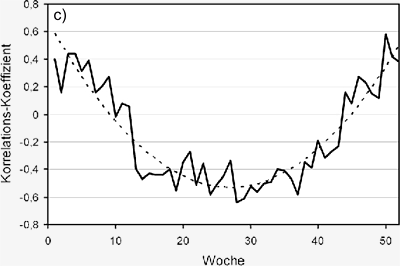
Abbildung 3.8: Ergebnisse der linearen wöchentlichen Regressionsanalyse
der Beziehung zwischen Mitteltemperatur
und Niederschlagssumme in den gemessenen Klimadaten
des Zeitraums 1960 bis 2006 (n=47) im Einzugsgebiet
der Oberen Donau a) Steigung, b) Achsenabschnitt, c)
Korrelationskoeffizient der Regressionsgeraden.
Abbildung S3.9: Prozentuale Veränderung der wöchentlichen
Niederschlagssumme zwischen 1990 und 2100 im
Klimatrend Fortschreibung bei einem angenommenen
Temperaturanstieg von 5.2°C von 1990 bis 2100 unter Nutzung
der historischen statistischen Beziehung zwischen
Temperatur und Niederschlag aus Abbildung S3.8.
Aus den statistischen Analysen lassen sich unter
der Annahme, dass sich die gefundenen statististatistischen
Beziehungen auf die zukünftigen meteorologischen
Verhältnisse übertragen lassen, die prozentualen Änderungen der wöchentlichen Niederschlagssumme
bei einer im Klimatrend Fortschreibung angenommenen Temperaturerhöhung
von 5.2°C im Zeitraum 1990 bis 2100 bestimmen.
Diese sind in Abbildung S3.9 dargestellt
und korrespondieren mit den Ergebnissen in Abbildung
S3.5.
Fasst man die prozentuale Veränderung des Niederschlags
in Abbildung S3.9 für die verschiedenen
Jahreszeiten zusammen, so ergeben sich die
in Tabelle S3.1 angegebenen Werte.
|
Niederschlagcveränderung
1990-2100 [%]
|
|
|
|
|
|
|
|
|
|
|
Tabelle S3.1: Jahreszeitliche Veränderung des Niederschlags
im Einzugsgebiet der Oberen Donau auf der
Grundlage des Klimatrends Fortschreibung.
Der in Abbildung S3.9 gezeigte Verlauf der prozentualen
Niederschlagsänderung im Einzugsgebiet
der Oberen Donau zwischen 1990 und
2100, der auf der Basis des historischen statistischen
Zusammenhangs zwischen Temperatur
und Niederschlag im Zeitraum von 1960 bis 2006
ermittelt wurde, ähnelt dem des Klimatrends
IPCC regional, der in Abbildung S3.5 dargestellt
wurde, zeigt allerdings bedeutend größere Ausschläge
im Winter wie auch im Sommer.
Validierung des statistischen Klimaantriebs-Generators
Voraussetzung für eine Nutzung des statistischen
Klimaantriebs-Generators im Projekt
GLOWA-Danube ist die erfolgreiche Validierung
des Ansatzes. Nachdem, wie in Abbildung S3.4
gezeigt, sicher gestellt ist, dass der Fehler bei der
Auswahl der ähnlichsten historischen Woche für
den meteorologischen Szenario-Datensatz nicht
mit der Szenario-Zeit anwächst, soll nun untersucht werden, wie gut der Klimaantriebs-Generator
dazu geeignet ist, das Klima der Vergangenheit
und seine statistischen Eigenschaften zu reproduzieren.
Hierzu wurden mit der beschriebenen
Methode vier synthetische meteorologische
Antriebe für die Jahre 1960 bis 2006 erzeugt. Sie
unterscheiden sich durch den jeweils gewählten
Startwert für den Zufallsgenerator. Die Startwerte
wurden wiederum zufällig ausgewählt, um eine
systematische Verzerrung der Ergebnisse zu vermeiden.
Die vier Datensätze sind zu dem gemessenen
Datensatz statistisch äquivalent, was im
betrachteten Fall bedeutet, dass sie:
- im Betrag und jahreszeitlichen Verlauf der
wichtigsten mittleren klimatologischen Parameter
Temperatur und Niederschlag mit den
gemessenen Klimadaten ähnlich sind, das
heißt der gleichen statistischen Grundgesamtheit
angehören. Für einen Vergleich wurden
die wöchentliche Mitteltemperatur und ihre
Streuung, die mittlere wöchentliche Niederschlagssumme
und ihre Streuung sowie die
Intensität der Niederschläge und die Anzahl
der Niederschlagsereignisse pro Woche herangezogen.
Die Nutzung des Zufallsgenerators
auf der Grundlage der aus den gemessenen
Daten bestimmten Mittelwerte und Kovarianzmatrizen
gewährleistet diese Annahme.
- für abgeleitete statistische meteorologische
Kennwerte des historischen Klimas vergleichbare
Werte wie die gemessenen Daten liefern.
Hierzu wurden die Kennwerte Jahresmitteltemperatur,
mittlere jährliche Niederschlagssumme,
Anzahl der Sommertage und Anzahl
der Frosttage gewählt.
- beim Antrieb von DANUBIA für statistische
hydrologische Kenngrößen vergleichbare
Werte liefern wie die gemessenen meteorologischen
Daten. Hierzu wurden die Kenngrößen
mittlerer Abfluss MQ, 1-jährlicher Hochwasserabfluss
HQ1, 100-jährlicher Hochwasserabfluss HQ100,100-jährlicher mittlerer 7-tägiger Niedrigwasserabfluss MN7Q100 sowie
die mittlere Dauerlinie am Pegel Achleiten
(Auslass des Einzugsgebiets der Oberen
Donau, A = 77 000 km²) sowie Oberaudorf am Inn gewählt (Zufluss des Inn nach Deutschland,
A = 9 000 km²).
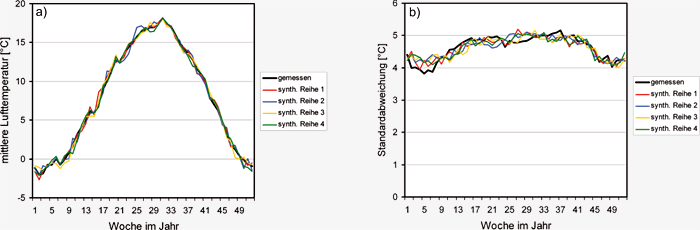
Abbildung S3.10: a) Vergleich der Verläufe der mittleren
wöchentlichen Mitteltemperaturen im Untersuchungsgebiet
für die Jahre 1960-2006 für die gemessenen und vier
synthetisch erzeugten Klimadatenreihen, b) Vergleich
der Standardabweichung der wöchentlichen Mitteltemperaturen
für die Jahre 1960-2006 für die gemessenen
und vier synthetisch erzeugten Klimadatenreihen.
In Abbildung S3.10a werden die Verläufe der
mittleren wöchentlichen Mitteltemperaturen im
Einzugsgebiet für den Zeitraum von 1960 bis
2006 aus dem gemessenen Datensatz mit denen
der synthetisch erstellten Datensätze verglichen.
Die Verläufe aller fünf Datensätze stimmen im
Wesentlichen überein. Abbildung S3.10b zeigt
die Standardabweichungen der wöchentlichen
Mitteltemperaturen um den Mittelwert aus Abbildung
S3.10a. Auch hier ist eine gute Übereinstimmung
zwischen den gemessenen und den
synthetisch erstellten Daten zu erkennen.
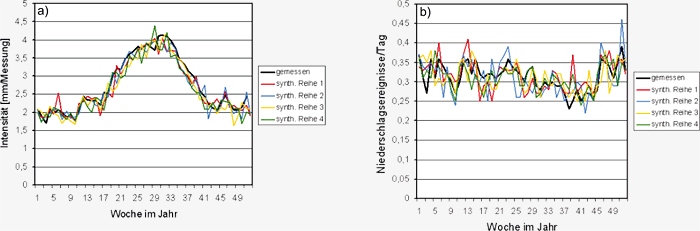
Abbildung S3.11: a) Vergleich der Jahresverläufe der
mittleren wöchentlichen gemittelten Niederschlagssummen
im Untersuchungsgebiet für die Jahre 1960-2006 für
die gemessenen und vier synthetisch erzeugten Klimadatenreihen,
b) Vergleich der Standardabweichung der
wöchentlichen gemittelten Niederschlagssummen für
die Jahre 1960-2006 für die gemessenen und vier synthetisch
erzeugten Klimadatenreihen.
Abbildung S3.11 zeigt die entsprechenden Verläufe
für die mittleren wöchentlichen über alle
Stationen gemittelten Niederschlagssummen.
Auch hier fällt die generelle Übereinstimmung
zwischen gemessenem und den synthetisch
bestimmten Verläufen auf, allerdings zeigen die
synthetisch erstellten Datensätze in manchen Wochen eine deutlichere Abweichung vom gemessenen
Mittelwert. Die in Abbildung S3.11b
gezeigte Streuung der wöchentlichen Niederschlagssummen
um den Mittelwert ist in allen Datensätzen
weitgehend identisch und nimmt mit
den konvektiven Niederschlägen im Sommer
stark zu.
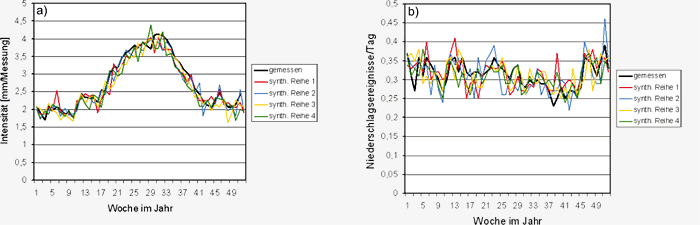
Abbildung S3.12: a) Vergleich der Verläufe der mittleren
wöchentlichen Niederschlagsintensität im Untersuchungsgebiet
für die Jahre 1960-2006 für die gemessenen
und vier synthetisch erzeugten Klimadatenreihen, b)
Vergleich der mittleren täglichen Anzahl von Niederschlagsereignissen
für die Jahre 1960-2006 für die gemessenen
und vier synthetisch erzeugten Klimadatenreihen.
Als weitere Kriterien für den Vergleich zwischen
den gemessenen und synthetisch erzeugten Klimadaten
wurden die mittlere Intensität des Niederschlags
(mm Niederschlag pro Messzeitpunkt)
sowie die mittlere Anzahl der Niederschläge
pro Tag herangezogen. Diese sollen zeigen,
ob sich die mittlere Dynamik der Niederschläge
bei der Erzeugung der synthetischen Datenreihen
verändert hat. Die Ergebnisse der Analyse in
Abbildung S3.12 bestätigen die große Übereinstimmung
der gemessenen und synthetischen
Klimadatenreihen.
Zusammenfassend sind in Tabelle S3.2 die Ergebnisse
der Analyse der vier Klimaparameter
Mitteltemperatur, Jahresniederschlag, Anzahl
der Sommertage und Anzahl der Frosttage sowohl
für die gemessenen als auch für die vier synthetisch
erzeugten Datenreihen über den Zeitraum
1960 bis 2006 gegenüber gestellt. Für die
Ermittlung der Klimaparameter wurden die Werte
aller Rasterzellen des Einzugsgebiets der Oberen
Donau gemittelt. Tabelle S3.2 zeigt, dass
auch die gewählten Klimaparameter für die gemessenen
und synthetisch erzeugten meteorologischen
Antriebe weitgehend übereinstimmen.
Als zweiter Schritt der Validierung des statistischen
Klimaantriebs-Generators wurden der gemessene
Datensatz und die vier synthetisch erzeugten
Datensätze als Eingabedaten für DANUBIA
genutzt, um für den Zeitraum von 1960 bis
2006 für jedes Proxel im Einzugsgebiet der Oberen
Donau den Abfluss stündlich zu berechnen
und auf Tageswerte zu aggregieren. Die Abflussdaten,
die unter Benutzung des gemessenen Datensatzes
erzielt wurden, entsprechen denen der
Karte 2.1.2, in der die Validierungen des hydrologischen
Teils von DANUBIA dargestellt sind. Für
die Abflusszeitreihen der 5 Simulationen wurden
die in Tabelle S3.3 dargestellten Größen ermittelt.
Während der mittlere Abfluss als Resultat der gemessenen
und synthetischen Antriebe ähnliche
Werte liefert, fällt zunächst eine deutliche Überschätzung
des HQ100 in Spalte 3 auf, der auf der
Grundlage von gemessenen Klimadaten berechnet
wurde. Die Überschätzung des HQ100 im
Modell ist vor allem auf die Vernachlässigung der
menschlichen Eingriffe auf den Hochwasserverlauf
durch gezielte Steuerung der vorhandenen
Speicher sowie auf die Vernachlässigung der
Ausuferung der Flüsse im Modell zurückzuführen. Beide haben bei den gehäuft auftretenden
großen Hochwässern vor allem im Zeitraum zwischen
1997 und 2005 zu einer Reduzierung der
gemessenen Hochwasserspitzen geführt. Weiter
fällt die starke Streuung der HQ100-Werte innerhalb
der Ergebnisse der vier benutzten synthetischen
Zeitreihen auf. Dies deutet darauf hin, dass
der HQ100 sehr empfindlich auf die in der betrachteten
Periode (hier 1960-2006) auftretenden
Extremniederschläge reagiert. Ebenfalls auffällig
ist die leichte Unterschätzung des NM7Q100 in den
Modellergebnissen mit gemessenen Daten
sowie eine mittlere bis starke Unterschätzung
des NM7Q100 in den Ergebnissen mit den synthetischen
Zeitreihen. Die leichte Unterschätzung
in Spalte 3 ist darauf zurückzuführen, dass
die in den letzten Jahren einsetzenden Maßnahmen
zur Niedrigwasseraufhöhung durch Nutzung
der Speicher im Einzugsgebiet im Modell z.Zt.
nicht abgebildet werden. Die Ursache für die mittlere
bis starke Unterschätzung des extremen
Niedrigwassers in den Ergebnissen der synthetischen
Zeitreihen konnte bisher nicht geklärt
werden.
| Zeitreihe 1960-2006 |
Gemessene Werte |
Synth.
Reihe |
Synth.Reihe 2 |
Synth.Reihe 3 |
Synth.Reihe 4 |
MittelwertSpalte 3-6 |
Mitteltemperatur [°C] |
7.95 |
7.79 |
7.92 |
8.14 |
8.00 |
8.00 |
| Jahres-Niederschlag [mm] |
1039.9 |
1034.6 |
1031.1 |
1060.0 |
1037.2 |
1040.7 |
| Anzahl Sommertage |
19,5 |
19,7 |
20,2 |
19,3 |
19,6 |
19,7 |
| Anzahl Frosttage |
130,6 |
129,2 |
131,5 |
133,2 |
131,7 |
131,4 |
Tabelle S3.2: Vergleich von Klimaparametern der gemessenen Daten mit den vier synthetischen Zeitreihen für das Einzugsgebiet
der Oberen Donau im Zeitraum 1960-2006.
|
aus Pegeldaten
1960-2006 |
modelliert mit
gem. Klimadaten |
modelliert mit
Synth.
Reihe 1 |
modelliert mit
Synth.
Reihe 2 |
modelliert mit
Synth.
Reihe 3 |
modelliert mit
Synth.
Reihe 4 |
Mittelwert
aus
Spalte 4-7 |
MQ |
1450.0 |
1498.1 |
1463.7 |
1456.5 |
1560.1 |
1454.0 |
1483.6 |
HQ1 |
3827 |
4206.4 |
3841.6 |
3900.3 |
3928.3 |
3506.1 |
3794.1 |
HQ100 |
6755 |
8187.4 |
6662.6 |
9987.4 |
6045.5 |
6828.5 |
7381.0 |
NM7Q100 |
476 |
418.9 |
350.7 |
345.6 |
291.4 |
296.7 |
321.7 |
Tabelle S3.3: Vergleich hydrologischer Kennwerte mittlerer Abfluss MQ, 1-jährlicher (HQ1), 100-jährlicher Hochwasserabfluss (HQ100) und 100-jährlicher mittlerer 7-tägiger Niedrigwasserabfluss NM7Q100 der vier synthetischen Zeitreihen und
deren Mittelwerte mit den am Pegel Achleiten gemessen Abflüssen und den mit den gemessenen Klimadaten modellierten
Abflüssen der Periode 1960 bis 2006.
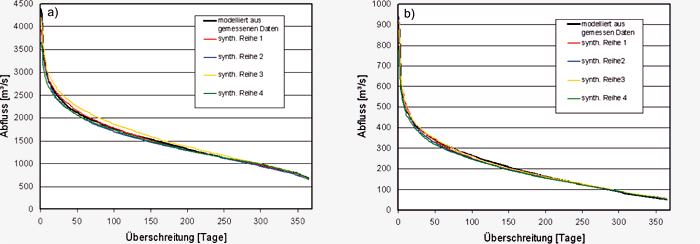
Abbildung S3.13: Überschreitungs-Dauerlinien für den
Zeitraum 1960-2006 für die mit den gemessenen Klimadaten
modellierten Abflüsse sowie für die 4 synthetischen
Datenreihen, a) Pegel Achleiten (Donau), b) Pegel Oberaudorf
(Inn).
Als dritter Schritt wurden die mit den gemessenen
und den synthetischen Datenreihen erzeugten
Dauerlinien an den Pegeln Achleiten am Ausgang
des Untersuchungsgebiets und Oberaudorf
am Ausgang des Inntals ins Alpenvorland miteinander
verglichen. Die Dauerlinien geben Auskunft
darüber, an wie vielen Tagen ein bestimmter
Abfluss über- bzw. unterschritten wird und stellen
damit die Dynamik des Abflusses im Untersuchungsgebiet
dar. Sie bilden eine wichtige Planungsgrundlage
für die Wasserwirtschaft und
speziell die Wasserkraftnutzung. In Abbildung S3.13a und S3.13b ist der Verlauf der mittleren
Dauerlinie an den Pegeln Achleiten bei Passau
und Oberaudorf für die Jahre 1960 bis 2006 dargestellt.
Die Resultate zeigen eine generell gute
bis sehr gute Übereinstimmung des Kurvenverlaufs
der Dauerlinie, die mit der gemessenen Datenreihe
modelliert wurde (schwarze Linie) und
der Dauerlinien, die mit den vier synthetischen Datenreihen
modelliert wurden (bunte Linien). In Abbildung
S3.13a fällt allerdings auf, dass die synthetischen
Dauerlinien teilweise über der mit gemessenen
Daten modellierten Dauerlinie liegen,
was auf die generelle leichte Überschätzung des
Niederschlages im statistischen Klimaantriebs-Generator zurückzuführen ist.
Schlussfolgerung
Zur Erzeugung von synthetischen meteorologischen
Antrieben, die mögliche zukünftige Entwicklungen
des Klimas darstellen können und die
gleichzeitig die zeitliche und räumliche Auflösung
besitzen, die für regionale Studien benötigt werden,
wurde ein statistischer Klimaantriebs-Generator
entwickelt. Er bewältigt den Skalenübergang
zwischen den Aussagen zur weiteren Entwicklung
des globalen Klimas und den für die regionalen
Klimawirkungsmodelle benötigten hoch
aufgelösten, physikalisch konsistenten meteorologischen
Eingaben. Seine Ergebnisse lassen
sich mit denen der regionalen Klimamodelle
vergleichen, die ähnliche Ziele verfolgen.
Es konnte gezeigt werden, dass der statistische
Klimaantriebs-Generator im historischen Zeitraum
von 1960-2006 das in diesem Zeitraum im
Untersuchungsgebiet herrschende Klima und die
daraus resultierenden Reaktionen des Einzugsgebiets
der Oberen Donau gut wiedergeben
kann. Der statistische Klimaantriebs-Generator
ist damit ein flexibles Werkzeug, um auf der
Grundlage der im Projekt entwickelten Klimatrends
die meteorologischen Antriebe für die Szenario-Simulationen bereitzustellen. Wie das Vorgehen
bei der Validierung des gewählten Ansatzes
gezeigt hat, ist es leicht möglich, durch
einfache Veränderung des Startwertes des verwendeten
Zufallsgenerators für jeden Klimatrend
eine Vielzahl von statistisch äquivalenten meteorologischen
Antrieben zu erzeugen und ihre Eintrittswahrscheinlichkeit
anzugeben. Dies wird in
Kapitel S4, in dem die GLOWA-Danube Klimavarianten
vorgestellt werden, genutzt.
Autor
W. Mauser
Department für Geographie, Lehrstuhl für Geographie und
geographische Fernerkundung, Ludwig-Maximilians-Universität
München
Literatur
Buishand, T. A. & Brandsma, T. (2001):
Multisite simulation
of daily precipitation and temperature in the Rhine Basin by
nearest–neighbour resampling. Water Resources Research,
Vol. 37, No.11, pp.2761-2776.
IPCC (2007):
Climate Change 2007: The Physical Science
Basis. Contribution of Working Group I to the Fourth Assessment
Report of the Intergovernmental Panel on Climate
Change [Solomon, S., D. Qin, M. Manning, Z. Chen, M.
Marquis, K.B. Averyt, M. Tignor and H.L. Miller (eds.)].
Cambridge University Press, Cambridge, United Kingdom
and New York, NY, USA, 996 pp.
Jacob, D., Göttel, H., Kotlarski, S.,Lorenz, P. & Sieck, K.
(2008):
Klimaauswirkungen und Anpassung in Deutschland -
Phase 1: Erstellung regionaler Klimaszenarien für Deutschland. In: Umweltbundesamt (Hrsg.) (2008): Climate Change
11/08.
Mahalanobis, P.C. (1936):
On the generalised distance instatistics. Proceedings of the National Institute of Science of
India Vol. 12, pp. 49-55.
Orlowsky, B., Gerstengarbe, F.W. & Werner, P.C. (2007):
A
resampling scheme for regional climate simulations and its
performance compared to a dynamical RCM. Theoretical and
Applied Climatology, Vol.92, No.3-4, pp. 209-223.
Spekat, A., Enke, W. & Kreienkamp, F. (2006):
Neuentwicklung von regional hoch aufgelösten Wetterlagen
für Deutschland und Bereitstellung regionaler Klimaszenarien
mit dem Regionalisierungsmodell WETTREG 2005 auf der
Basis von globalen Klimasimulationen mit ECHAM5/MPI –
OM T63L31 2010 bis 2100 für die SRES – Szenarien B1, A1B
und A2. Projektbericht im Rahmen des F+E- Vorhabens 204
41 138 „Klimaauswirkungen und Anpassung in Deutschland –
Phase 1: Erstellung regionaler Klimaszenarien für Deutschland“,
94 S.
Visual Numerics (2006):
IMSL FORTRAN Numerical Library
User’s Guide Version 6, Visual Numerics Ltd, Houston, Texas.
Yates, D., Gangopadhyay, S., Rajagopalan, B. and
Strzepek, K. (2003):
A technique for generating regional
climate scenarios using a nearest neighbour algorithm. Water
Re-sources Research, Vol. 39, No. 7, pp. 1-15.
Young, K.C. (1994):
A multivariate chain model for simulating
climatic parameters from daily data. Journal of Applied
Meteorology, Vol.33, 661–671.
 Diese Seite als PDF runterladen. Diese Seite als PDF runterladen.
zurück zur Szenarien-Übersicht

|

